ABBYY FlexiCapture

ABBYY FlexiCapture je inteligentné riešenie pre vyťažovanie dát z dokumentov bez nutnosti ručného vyhľadávania údajov a ich prepisovania alebo kopírovania. Je určené všetkým firmám a organizáciám, ktoré pracujú s desiatkami, stovkami až tisícmi dokumentov denne a hľadajú riešenie, ako zefektívniť procesy súvisiace so spracovaním dokumentov. Práve tým je ABBYY FlexiCapture určené – s jeho pomocou je možné výrazne znížiť dobu potrebnú k spracovaniu dokumentov, významnú časť spracovania plne automatizovať a získaný čas zamestnancov využiť inak – lepšie.
Požiadavky, ktoré ABBYY FlexiCapture rieši:
- automatizované triedenie dokumentov, ich klasifikácia, indexovanie a vyťažovanie dát zo všetkých typov dokumentov
- možnosť rýchleho nasadenia a jednoduchého použitia
- škálovateľnosť a optimalizovaný výkon
- flexibilní nástroje pre integráciu a prispôsobenie
- plná kompatibilita s bežnými štandardmi
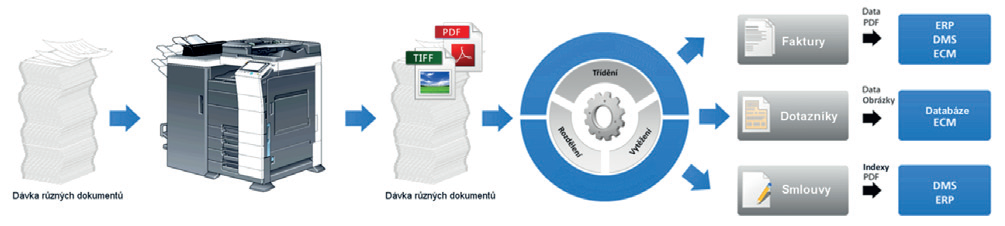
Triedenie a rozpoznávanie dokumentov
ABBYY FlexiCapture ponúka jak jednoduchú separáciu, tak pokročilú klasifikáciu dokumentov. Identifikuje typ dokumentu a skladá jedno i viacstránkové dokumenty z dávky s využitím najmodernejších technológií ABBYY, ktoré umožňujú samo-učenie, a vďaka tomu zvláda veľmi presne rozpoznávať:
- viacstránkové dokumenty
- dokumenty s premenným počtom strán
- dokumenty, ktoré obsahujú viacstránkové tabuľky a zoznamy
- dokumenty s obrazovými alebo textovými prílohami
Vyťažovanie dát
Pomocou veľmi kvalitného viacjazyčného rozpoznávania vyťažuje ABBYY FlexiCapture presne dáta a text z polí, špecifických pre každý typ dokumentu.
Technológia ABBYY FlexiCapture ponúka prakticky neobmedzené možnosti digitalizácie dát a poskytuje aj v najzložitejších prípadoch veľmi presné výsledky. Pre vyťažovanie dát používa ABBYY FlexiCapture tieto rozpoznávacie technológie:
- OCR pre rozpoznávanie strojovo písaného textu (podpora viac ako 180 jazykov vrátane češtiny a slovenčiny)
- OMR (rozpoznávanie značiek) pre široké spektrum zaškrtávacích políčok a kontrolu prítomnosti podpisov
- ICR (Intelligent Character Recognition – inteligentné rozpoznávanie znakov) pre rozpoznávanie ručne písaného textu (podpora viac než 110 jazykov vrátane češtiny a slovenčiny)
- Rozpoznávanie rôznych typov 1D a 2D kódov
Typy edícií
- Edícia Standalone
Základná varianta určená malým a stredným podnikom, kde sa očakáva, že sa softvér bude používať na jednom mieste/počítači. Výhodou je jednoduchá inštalácia, poskytujúca celou škálu možností vyťažovania dát pri importu dokumentov a exportu dát.
- Edícia Server
Ideálna pre použitie v kombinácii s multifunkčným zariadením, ktoré kladie požiadavky na čo najvyššiu automatizáciu spracovania a vyťažovania dokumentov. Edíciu Server je možné škálovať a zrýchliť tak dobu spracovania.
- Edícia Distributed
Je určená pre veľkoobjemové spracovania až miliónov dokumentov za deň. Umožňuje oddeliť fázy digitalizácie dokumentov, pružne prideľovať úlohy i zdroje a nastaviť postup tak, aby splňoval scenár požadovaného spracovania. Distribuovaná inštalácia dokonale splňuje požiadavky veľkých podnikov, nadnárodných korporácií i outsourcingových projektov na rýchlosť a predovšetkým kvalitu spracovania vďaka užívateľsky prívetivým nástrojom pre rýchle overenie a prípadné opravovanie dát (a to vrátane webového prístupu pre práci „v teréne“). Edícia Distributed je tiež vhodná pre použitie v štátnych organizáciách.