ABBYY Recognition Server

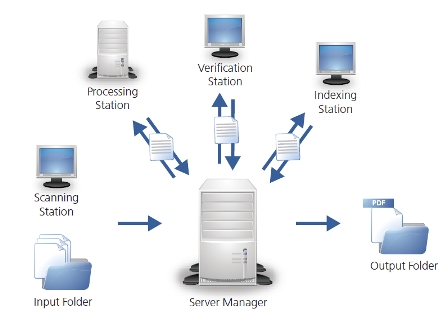
ABBYY Recognition Server je robustným serverovým riešením, ktoré umožňuje organizáciám efektívny prevod papierových dokumentov alebo ich obrazov do prehľadávateľných a opätovne použiteľných elektronických súborov. Výkonná technológia podporuje skenovanie dokumentov, veľmi presne rozpoznanie celého textu a vyťažovanie metadát, čo umožňuje dodanie dát, vhodných pre elektronické archívy, Enterprise Content Management systémy (podnikovú správu obsahu), vyhľadávanie a ďalšie. Škálovateľná architektúra umožňuje vysoký objem spracovania, dovoľujúci efektívne a centrálne riadené nasadenie.
Vlastnosti
Vstup a skenovanie
ABBYY Recognition Server ponúka aplikáciu pre priame skenovanie do Recognition Serveru. Scanning Station (skenovacia stanica) podporuje skenovacie rozhranie TWAIN, WIA a ISIS a poskytuje nástroje pre vizuálne riadenie kvality dokumentov pred rozpoznaním. Nástroje pred rozpoznaním, dostupné na Scanning Station (skenovacej stanici) zahrňujú náhľad dokumentu, vylepšenie obrazu, definíciu typu dávok, ručnú korekciu a triedenie poradia stránok.
Integrácia s MS SharePoint
Riešenie umožňuje úpravy, vytváranie textovej vrstvy a konverziu priamo v knižniciach SharePointu a previesť tak celý doterajší archív na plne full-textovo prehľadávateľný.
Rozpoznanie a konverzia PDF
- Predspracovanie obrazu: rozdelenie dvojstránok (pre skeny kníh), prevod farieb na čiernu a bielu, vymazanie šumu pozadia a ďalšie
- Typ tlače: výber medzi normálnym textom, znaky písacieho stroja, znaky z rastrových bodov, OCR-A, OCR-B a MICR (E13b)
- Jazyky: výber z viac než 190 jazykov, presné spracovanie i viacjazyčných dokumentov
- Neobvyklé písma: podpora gotického písma, švabachu a väčšiny iných gotických písiem, tlačených medzi rokmi 1700 a 1937 anglicky, nemecky, francúzsky, taliansky a španielsky
- Čiarové kódy: rozpoznáva najpopulárnejšie jedno a dvojrozmerné čiarové kódy vrátane 2D Aztec, Data Matrix a QR Code, bez ohľadu na uhol alebo umiestenie na dokumente
- 3 rôzne režimy rýchlostí spracovania: presnosť, rýchlosť a vyrovnaný režim
Prispôsobenie skriptovaním
Využitím skriptovania môžu užívatelia prispôsobiť interné spracovanie, obsluhu výnimiek a export dokumentov. Rôzne druhy skriptov je možné použiť k vytvoreniu flexibilnejších pravidiel separácie dokumentov, automatizovaného jednoduchého indexovania, pridanie funkcií dynamického a prispôsobeného exportu a zjednodušenie publikácie výstupných dokumentov do interných systémov. Skripty môžu byť použité tiež k obsluhe výnimiek pre riadenie spracovania dokumentov, vyžadujúcich zvláštnu pozornosť.
Kontrola kvality a overovania
Verification Stations (overovacie stanice), ktoré môžu byť inštalované na viacerých pracovných staniciach a riadené prostredníctvom súbežných licencií, umožňujú obsluhe ručnú kontrolu alebo overenie výsledkov spracovania. Overovatelia môžu skontrolovať rekonštruované rozloženie (obrázkov, textu, tabuliek), upraviť rozpoznaný text a skontrolovať pravopis.
Separácia a pomenovanie dokumentov
Recognition Server môže ako oddeľovače dokumentov využívať prázdne stránky alebo čiarové kódy. Je tiež možné vytvárať dokumenty s pevným počtom stránok a dokumenty v určitom priečinku je možné tiež zlúčiť do jediného dokumentu. Užívatelia môžu rovnako zvoliť konvencie automatického vytvárania názvov dokumentov pomocou vlastností ako je dátum, čas, určitý text a hodnoty čiarových kódov. Pomocou riadenia skriptovaním môžu správcovia tiež vytvoriť vlastné pravidla pre separáciu dokumentov.
Klasifikácia a indexovanie ukáž-a-klikni
- Zápis indexov: obsluha zadáva indexy ručne
- Indexovanie "ukáž-a-klikni": obsluha vyberá kľúčové slová do indexov ukázaním a kliknutím v obraze dokumentu
- Indexovanie kľúčovými frázami: pre vytvorenie osnovy viet, niekoľko riadkov alebo odstavcov používa obsluha funkcie "gumové pásky"
- Správcovia môžu automatické funkcie indexovania vytvárať a definovať tiež na základe štruktúry a obsahu dokumentu pomocou skriptov